MCP for Kubernetes: Live Cluster Context for AI Tools
Pointing an AI at raw kubectl works, badly. Radar's built-in MCP server gives Claude, Cursor, and friends a token-optimized, RBAC-aware view of your cluster.
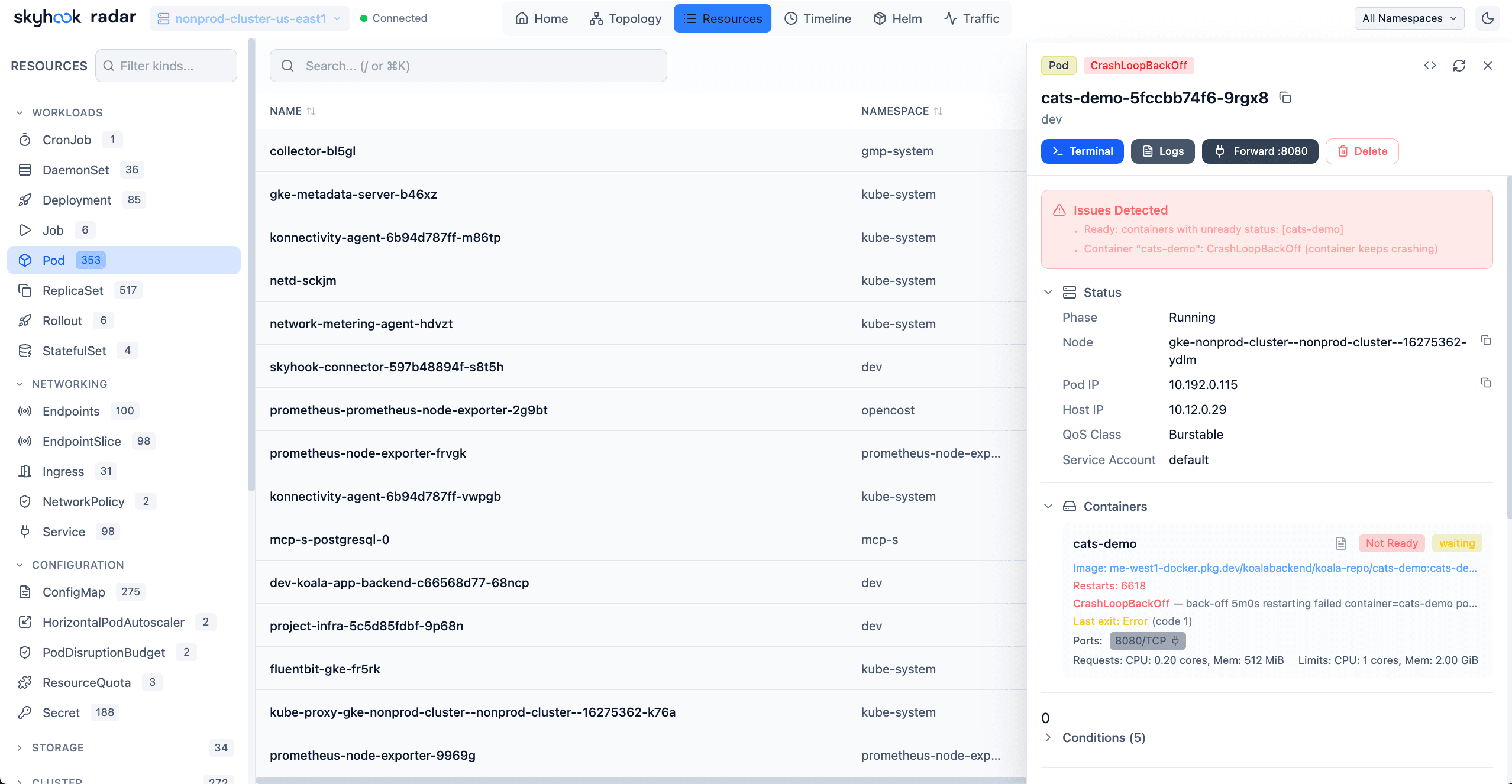
The first time I asked Claude to debug a CrashLoopBackOff via raw kubectl access, it spent 4,000 tokens parsing a single Pod's YAML before it noticed the OOMKilled status condition. The condition was the second-to-last field. Everything before it was managedFields, status I didn't ask for, and annotations that had nothing to do with the question.
That's the failure mode of giving an AI raw cluster access. The tool works - it can read, it can run commands - but the signal-to-token ratio is terrible. You burn budget on noise before getting to the useful part, and even then the AI has no idea which events relate to which workload, what's owned by what, or which Secret values it must never read.
Radar ships a built-in MCP server that fixes this. Same surface area as the UI, packaged for token efficiency and protected by your existing RBAC.
What's wrong with raw kubectl
Three things break when you point an AI at unfiltered cluster access.
Token waste. A single kubectl get pod -o yaml is 2-3 KB of managedFields, internal annotations, and status fields nobody asked for. Across a namespace with 80 pods, you're spending ten thousand tokens before the AI has even seen one useful piece of state.
No correlation. Raw output doesn't relate Pods to Services to Ingresses, doesn't dedupe events, doesn't know which logs are interesting. When you ask "why is the api Deployment unhealthy?", the AI has to fetch the Deployment, then the ReplicaSet, then the Pods, then the events, then the logs - five separate tool calls, each returning more raw YAML, each costing tokens. Most of the round-trips you can skip if the tool surface is shaped right.
Unrestricted writes. kubectl can modify or delete anything the user behind the kubeconfig can. Giving an AI agent that level of authority makes you nervous, and it should. Even with --dry-run=client everywhere, one missed flag and you've nuked a production resource.
What Radar's MCP server gives an AI instead
Four properties that change the math.
Resources are minified. managedFields, last-applied-configuration, redundant status fields, and internal annotations are stripped before they hit the wire. The meaningful spec and status are kept. A Pod that costs 3 KB through raw kubectl typically costs ~600 bytes through Radar's MCP. You can fit ten times more cluster into the same context window.
Resources are enriched. get_resource accepts an include parameter (events,relationships,metrics,logs) that returns the related signals in one call. Topology relationships, deduped events, secret-safe logs, observed metrics. The AI doesn't have to build a mental model of how Kubernetes objects own each other - the tool answers correlation questions directly.
Writes are explicitly safe. No raw delete. No force-uninstall. No --cascade=orphan. The write tools are a curated set: apply_resource, manage_workload (restart, scale, rollback), manage_cronjob (trigger, suspend, resume), manage_gitops (sync, reconcile, suspend), manage_node (cordon, uncordon, drain). They're tagged so MCP clients that distinguish read-only from write can present them differently, and most read-only AI workflows never touch them.
Secrets and tokens are scrubbed. Secret .data and .stringData never leave the cluster. Env values get redacted by pattern. Log lines are scrubbed for known secret shapes (API keys, JWTs, base64 blocks of suspicious entropy). The AI literally cannot see a Secret value, even if you ask it to.
The tool list
Compact view of what's wired up.
| Read tool | What it returns |
|---|---|
get_dashboard | Cluster health overview - counts, problems, warnings, Helm status, recent changes |
list_resources | Resources of a kind, minified summaries |
get_resource | One resource, optionally with events,relationships,metrics,logs |
get_topology | Resource relationships graph (or text summary) |
get_events | Recent events, deduplicated, optionally scoped to a resource |
get_pod_logs | Filtered logs (errors / warnings prioritized, secrets scrubbed) |
get_workload_logs | Aggregated logs across pods of a workload |
list_namespaces | Namespaces with status |
get_changes | Recent resource changes from the timeline |
list_helm_releases | Helm releases with status |
get_helm_release | Detailed release info; optional values,history,diff |
list_packages | What's installed across Helm, workload labels, CRDs, Argo CD Applications, and Flux. Each row carries a sources array so you can see why a package was detected, plus per-source health and version |
audit_findings | Cluster audit findings, filterable by category and severity |
list_clusters (Cloud) | Clusters in the current org |
| Write tool | What it does |
|---|---|
apply_resource | Create / update from YAML, multi-doc, supports dry_run |
manage_workload | restart / scale / rollback Deployments, StatefulSets, DaemonSets |
manage_cronjob | trigger / suspend / resume |
manage_gitops | Argo or Flux: sync / reconcile / suspend / resume |
manage_node | cordon / uncordon / drain |
There's also a cluster:// URI scheme for the resource style: cluster://health, cluster://topology, cluster://events. Useful for MCP clients that prefer resources over tool calls.
Setup
OSS Radar exposes MCP on the same port as the UI (default 9280), localhost-only.
For Claude Code:
claude mcp add radar --transport http http://localhost:9280/mcpFor Cursor (~/.cursor/mcp.json):
{ "mcpServers": { "radar": { "url": "http://localhost:9280/mcp" } } }For Claude Desktop (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"radar": {
"type": "http",
"url": "http://localhost:9280/mcp"
}
}
}Windsurf, VS Code Copilot, JetBrains AI, OpenAI Codex, Gemini CLI - same shape, different config file. The docs cover each in detail.
For Cloud, every cluster has its own MCP endpoint gated by a personal access token:
{
"mcpServers": {
"radar-prod": {
"type": "http",
"url": "https://api.radarhq.io/c/<cluster_id>/api/mcp",
"headers": { "Authorization": "Bearer rhp_..." }
}
}
}The dashboard's Connect an AI client wizard auto-fills the snippet for whichever tool you pick. Cloud also exposes a list_clusters tool on the org-wide endpoint, so a multi-cluster AI workflow can ask "what clusters do I have access to?" without you hardcoding cluster IDs.
RBAC: the part that surprised some early users
Each MCP call goes through Kubernetes with the user's identity, not a shared agent identity. In OSS, that's whatever your kubeconfig grants. In Cloud, the in-cluster Radar pod impersonates the user (via X-Forwarded-User and X-Forwarded-Groups headers injected by Cloud), so a cloud:viewer user's MCP calls hit the cluster as a view-level identity. A 403 from K8s comes back as a 403 from MCP.
This means an AI agent inherits the permissions of whoever's running it. A read-only engineer's AI can read. An admin's AI can write the things admins can write. Nobody has to maintain a "service account for AI" that's secretly more privileged than the humans using it.
What this changes about debugging
The honest answer is that it changes a workflow, not a productivity multiplier.
A typical debugging session with this in place looks like:
- Page fires, you open the AI chat.
- "The api Deployment in prod is unhealthy. What changed in the last hour?"
- AI calls
get_dashboard, thenget_resource Deployment/api include=events,relationships, thenget_changes since=1h kind=ConfigMap namespace=prod. - AI reports back: "ConfigMap
api-configwas patched 47 minutes ago. Thecache.preload_on_startupfield flipped fromfalsetotrue. The first OOMKill on the api pods was 3 minutes after that." - You decide whether to revert.
It's not magic. The AI didn't fix anything. It just stitched the timeline together using tools that knew how Kubernetes objects relate to each other. Without MCP, that stitch takes the AI a lot of token-expensive raw YAML reads to figure out, and it's about a 50/50 shot whether it gets there before context runs out.
With it, the stitch is the first three tool calls, and the answer is in the first response.
What MCP isn't
Two honest gaps.
Not a replacement for the UI. I use both. MCP is for "I want to ask a question and get an answer." The UI is for "I want to see the shape of the cluster and decide what to do." They serve different jobs.
Not a replacement for runtime safety. The write tools are curated to be non-destructive. They're not a substitute for code review on what your AI agent decides to do. Treat AI-driven apply_resource calls the same way you'd treat a human applying YAML against prod - with a dry-run, a review, and a willingness to roll back.
The shape of it
The reason MCP-via-Radar works better than MCP-via-kubectl is that we'd already done the work of minifying, correlating, and securing cluster reads for the UI. Exposing the same surface area to AI tools is a small additional step on top of that, and the result is a context window that doesn't get burned on managedFields and a write surface that doesn't let the AI delete prod by accident.
If you're already running Radar, MCP is on by default. If you're not, the open-source binary is the fastest way to point Claude or Cursor at one of your clusters and see what changes - install steps are at radarhq.io/docs.
Keep reading
Agents, UIs, and CLIs: The False Choice in Kubernetes Operations
Kubernetes ops spans three surfaces: CLI, UI, and AI agent. kubectl is fine, but a live cluster graph deserves better than raw YAML - for humans and agents alike.
Cluster Audit: The 31 Checks That Catch What You Forgot
Most clusters fail the same checks. Radar's built-in audit runs 31 of them inline against your live state. Inspired by Polaris and the NSA / CISA hardening guide.
Radar OSS or Radar Cloud? An Honest Take on When to Use Each
The most common question in our GitHub issues: do I need Radar Cloud, or is OSS enough? Here's the honest answer, with the five questions that actually decide it.